Parquet: What is and How it stores data
Discover the power of Apache Parquet, a high-performance columnar storage format designed for big data analytics. Learn how its metadata, compression, and schema evolution optimize query performance and reduce storage costs, making it the ideal choice for modern data processing.


A concise, practical guide to Apache Parquet, focused on its structure, advantages, and how it stores data efficiently.
Introduction
Apache Parquet was introduced in 2013 by engineers at Twitter and Cloudera as an open-source, columnar storage format designed for high-performance data processing. The goal was to create a storage format optimized for modern big data processing frameworks – an efficient, compressed, and schema-aware columnar format.
Why?
- Parquet is widely used in distributed computing frameworks because of its efficient columnar storage and high compression rates, making it ideal for large-scale data processing.
- Parquet is deeply integrated into cloud-native analytics services, allowing efficient querying directly from object storage.
- Parquet is extensively used in data preprocessing and feature engineering due to its fast I/O performance and efficient storage.
- Modern data lakehouse architectures leverage Parquet to store structured and semi-structured data efficiently (see my blogposts about Delta Lakes).
Parquet vs. Row-Based Formats
Traditional row-based storage formats (CSV, JSON, Avro, etc) store data row by row, which works well for transactional workloads but is inefficient for analytics.
| Format | Characteristics | Limitations |
|---|---|---|
| CSV | Simple, human-readable, widely used | No schema, large file sizes, inefficient parsing |
| JSON | Flexible, supports nested structures | Verbose, slow to parse, high storage overhead |
| Avro | Binary format with schema evolution | Optimized for write-heavy workloads, but slower reads |
Apache Parquet stores data column-wise, significantly improving analytics workloads, given the following reasons:
- Columnar Storage – Reads only the needed columns, reducing I/O.
- Efficient Compression – Similar values are stored together, enabling better compression.
- Schema Evolution – Supports adding new columns without breaking compatibility.
- Predicate Pushdown – Filters data at the storage level, avoiding unnecessary reads. It is an optimization technique that reduces the amount of data read from storage by applying filters early, before data is loaded into memory for processing.
- Parallel Processing – Column chunks can be read in parallel, improving performance.
How Parquet Stores Data Internally
Columnar Storage Explained
Instead of storing data row by row, Parquet stores all values of a single column together. This approach improves performance because analytical queries typically access a subset of columns rather than entire rows.
Let's take the following dataset for example:
| ID | Name | Age | Salary |
|---|---|---|---|
| 1 | John | 30 | 50000 |
| 2 | Alice | 28 | 60000 |
Row-based format:
ID, Name, Age, Salary
1, John, 30, 50000
2, Alice, 28, 60000Columnar format:
ID: 1, 2
Name: John, Alice
Age: 30, 28
Salary: 50000, 60000File Structure of Parquet
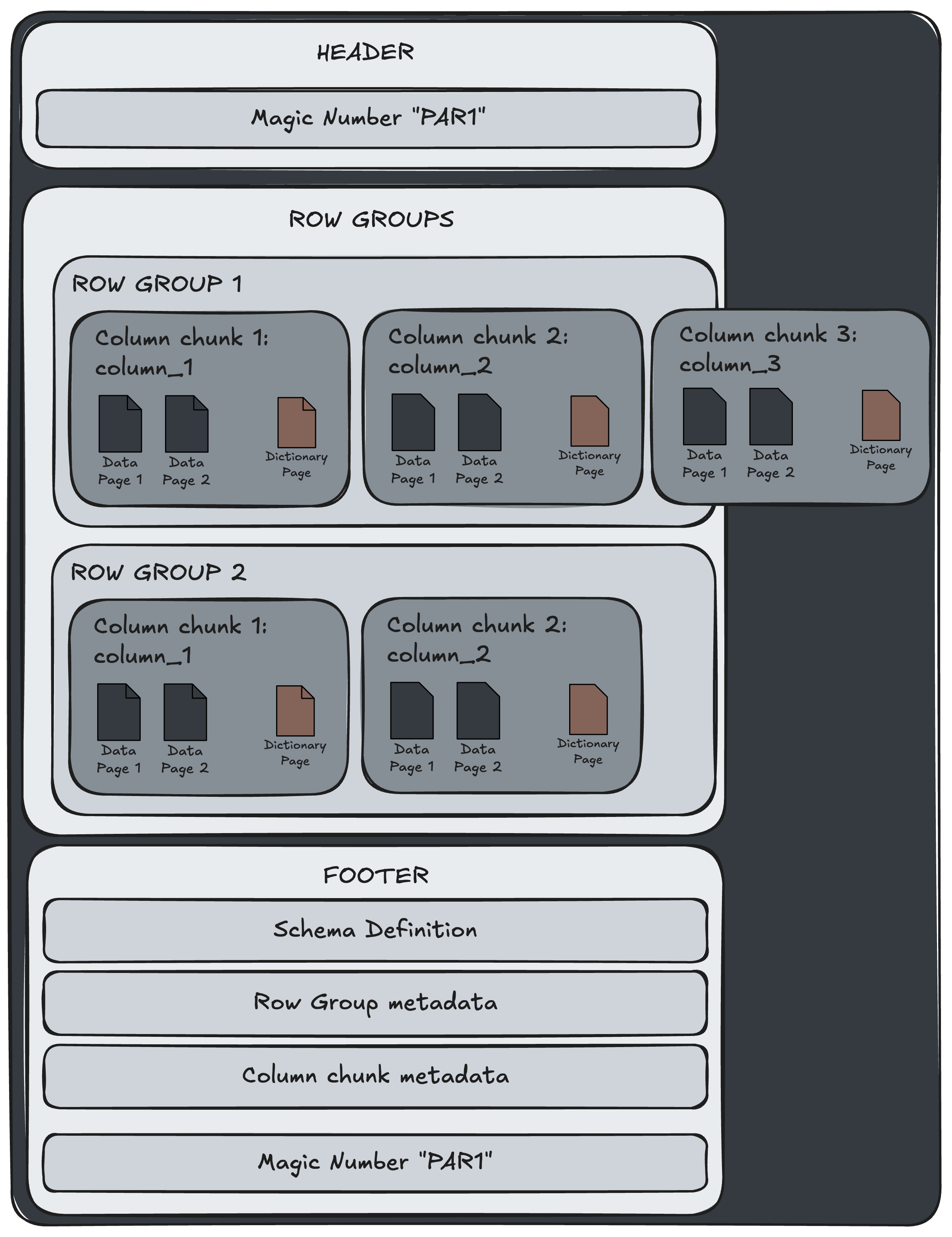
A *.parquet file has 3 main components:
- Header - used to identify file as Parquet file
- Row Groups - actual data
- Footer - metadata
Example:
| Header | Row Group 1 | Row Group 2 | ... | Footer | Magic Number |Header
- Size: 4 bytes
- Content: Hardcoded value of "PAR1"
- Purpose: used solely to identify file as Parquet
Row Groups
- Size: variable (depends on data size)
- Content: Compressed and Encoded actual data storage
Row groups are a list of independent chunks of data. It can be essentially considered to be a tree, containing column chunks which in turn are split into pages, etc.
Each Column is stored separately in a columnar format within the Row group, which allows for efficient compression and fast columnar queries.
Each Column chunk is divided into Pages. Column Pages contain actual values which are compressed and encoded. Diving deeper you might find that pages can also be Dictionary Pages which store unique values for dictionary encoding or even Index Pages storing indexing data for faster lookups.
Footer
- Size: variable (depends on metadata size)
- Content:
- File metadata: schema, encoding, etc...
- Row Group metadata: offsets and statistics
- Schema definition: column names, data types
- Magic Number "PAR1" repeated at the end for validation
- Purpose: used for fast scanning without reading the full file. Allows for efficient column pruning.
Metadata: The Key to Performance
Parquet’s metadata plays a crucial role in optimizing storage and query performance. Parquet stores rich metadata in the footer, enabling efficient column pruning, predicate pushdown, and parallel reads. Below is an example of how Parquet metadata is structured:
Metadata
├── File Metadata
│ ├── Schema
│ ├── Row Groups
│ ├── Key-Value Metadata (Optional)
│ ├── Created By (Optional)
│ ├── Column Orders (Optional)
│ ├── Encryption Metadata (Optional)
│ ├── Version Number
│ ├── Footer Length
│ ├── Magic Number ("PAR1")Metadata fields
Schema
Defines the structure of the file (columns, types, nesting).
Example schema for a file with id (INT), name (STRING), age (INT):
Schema
├── Root (Message Type)
│ ├── id: INT32
│ ├── name: BYTE_ARRAY (STRING)
│ ├── age: INT32- Message Type: The root-level structure.
- Primitive Types:
INT32,BYTE_ARRAY,BOOLEAN, etc. - Nested Structures: Supports lists, maps, and structs (nested data).
Row Groups
Contains metadata about row groups and their column chunks.
Row Group 1 Metadata
├── Total Rows: 100,000
├── Total Byte Size: 10 MB
├── Column Chunks
│ ├── Column: id
│ │ ├── Encodings: RLE, BIT_PACKED
│ │ ├── Compression: Snappy
│ │ ├── Data Page Offset: 1024
│ │ ├── Total Compressed Size: 3 MB
│ ├── Column: name
│ │ ├── Encodings: PLAIN, DICTIONARY
│ │ ├── Compression: Gzip
│ │ ├── Data Page Offset: 4096
│ │ ├── Total Compressed Size: 5 MBEach row group:
- Tracks offsets for quick access.
- Stores compression details.
- Lists encodings used for space efficiency.
Key-Value Metadata
Stores custom metadata. Commonly used for processing history, job details, or extra info.
Key-Value Metadata
├── "created_by": "Apache Spark 3.1"
├── "dataset_version": "1.0"
├── "source": "data_pipeline_X"Why is Parquet So Efficient?
- Column Pruning: Queries only read relevant columns.
- Predicate Pushdown: Queries skip irrelevant rows based on filters.
- Compression: Columnar storage allows better compression ratios.
- Efficient Reads: Spark/Trino/Presto don’t need to read the whole file—just the needed parts.
When to Use Parquet?
- Good for:
- Large-scale analytics & BI workloads.
- Storing data in data lakes (AWS S3, Azure, GCP).
- Use cases where fast querying & low storage cost matter.
- Not Ideal for:
- Small, frequently updated transactional databases.
- Real-time streaming writes.
Conclusion & Further Reading
In summary, Apache Parquet's columnar storage format offers significant advantages for data analytics and processing. By storing data by columns rather than rows, Parquet enables efficient data compression and encoding, which reduces storage requirements and enhances query performance. Its support for schema evolution allows for flexibility in data modeling, accommodating changes over time without sacrificing compatibility. These features make Parquet a preferred choice for modern data processing frameworks, facilitating efficient and scalable data analytics workflows.

